一个Bad gateway的bug
2015-07-16
线上机器有回调的接口,会时不时的报502 Bad Gateway的错误,本来也没什么,但是天天每隔几分钟来一条报警的短信,很烦的。让sa那边把报警取消了他们又说这个业务不能取消,只能尝试解决一下了。
首先上网查了一下,都是什么配置错误啊,程序错误啊之类的。
但是我们的问题诡异就诡异在:PHP层面没有任何报错的信息。而且配置错误是一个非常小概率的事情,差不多100台机器只有两台报警而且不会影响到线上的业务。(最主要的原因是改配置的话需要所有机器都改一遍,在流量小的情况下是不会报警的,测试风险和成本太大,所以只能从别的地方入手)。
遇到bug不可怕,但是那种没有线索的bug才是让人头疼的。
那么既然php层面没有问题,那么就来看nginx层面,通过对报警时间和日志的分析,发现报警前几乎error.log里面都会有这样一段日志:
2015/07/15 09:24:04 [error] 10853#0: *6453 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 219.136.34.244, server: 203.20.249.124, request: "POST /api.php/pay/uc/callback HTTP/1.1", upstream: "fastcgi://127.0.0.1:7777", host: "203.20.249.124:81"
这是nginx的错误日志, 看字面意思是nginx发现没有存活的后端了,但是很奇怪的事情是,这段时间一直访问都正常。
现在只能从nginx源码的角度来看了。
因为是upstream有关的报错,所以在ngx_http_upstream.c中查找“no live upstreams”的关键字,可以找到如下代码(其实,你会发现,如果在nginx全局代码中找的话,也只有这个文件里面有这个关键字):
rc = ngx_event_connect_peer(&u->peer);
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, r->connection->log, 0, "http upstream connect: %i", rc);
if (rc == NGX_ERROR) {
ngx_http_upstream_finalize_request(r, u, NGX_HTTP_INTERNAL_SERVER_ERROR);
return;
}
u->state->peer = u->peer.name;
if (rc == NGX_BUSY) {
ngx_log_error(NGX_LOG_ERR, r->connection->log, 0, "no live upstreams");
ngx_http_upstream_next(r, u, NGX_HTTP_UPSTREAM_FT_NOLIVE);
return;
}
if (rc == NGX_DECLINED) {
ngx_http_upstream_next(r, u, NGX_HTTP_UPSTREAM_FT_ERROR);
return;
}
在这里可以看出,当rc等于NGX_BUSY的时候,就会记录“no live upstreams”的错误。
往上看,可以发现rc的值又是ngx_event_connect_peer这个函数返回的。
ngx_event_connect_peer是在event/ngx_event_connect.c中实现的。这个函数中,只有这个地方会返回NGX_BUSY,其他地方都是NGX_OK或者NGX_ERROR或者NGX_AGAIN之类的。
rc = pc->get(pc, pc->data);
if (rc != NGX_OK) {
return rc;
}
这里的pc是指向ngx_peer_connection_t结构体的指针, get是个ngx_event_get_peer_pt的函数指针,具体指向哪里,一时无从得知。接着翻看ngx_http_upstream.c,在ngx_http_upstream_init_main_conf中看到了,如下代码:
uscfp = umcf->upstreams.elts;
for (i = 0; i < umcf->upstreams.nelts; i++) {
init = uscfp[i]->peer.init_upstream ? uscfp[i]->peer.init_upstream: ngx_http_upstream_init_round_robin;
if (init(cf, uscfp[i]) != NGX_OK) {
return NGX_CONF_ERROR;
}
}
这里可以看到,默认的配置为轮询(事实上负载均衡的各个模块组成了一个链表,每次从链表到头开始往后处理,从上面到配置文件可以看出,nginx不会在轮询前调用其他的模块),并且用ngx_http_upstream_init_round_robin初始化每个upstream。 再看ngx_http_upstream_init_round_robin函数,里面有如下行:
r->upstream->peer.get = ngx_http_upstream_get_round_robin_peer;
这里把get指针指向了ngx_http_upstream_get_round_robin_peer。 在ngx_http_upstream_get_round_robin_peer中,可以看到:
if (peers->single) {
peer = &peers->peer[0];
if (peer->down) {
goto failed;
}
} else {
/* there are several peers */
peer = ngx_http_upstream_get_peer(rrp);
if (peer == NULL) {
goto failed;
}
}
再看看failed的部分:
if (peers->next) {
/* ngx_unlock_mutex(peers->mutex); */
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, pc->log, 0, "backup servers");
rrp->peers = peers->next;
n = (rrp->peers->number + (8 * sizeof(uintptr_t) - 1)) / (8 * sizeof(uintptr_t));
for (i = 0; i < n; i++) {
rrp->tried[i] = 0;
}
rc = ngx_http_upstream_get_round_robin_peer(pc, rrp);
if (rc != NGX_BUSY) {
return rc;
}
/* ngx_lock_mutex(peers->mutex); */
}
/* all peers failed, mark them as live for quick recovery */
for (i = 0; i < peers->number; i++) {
peers->peer[i].fails = 0;
}
/* ngx_unlock_mutex(peers->mutex); */
pc->name = peers->name;
return NGX_BUSY;
这里就真相大白了,如果连接失败了,就去尝试连下一个,如果所有的都失败了,就会进行quick recovery 把每个peer的失败次数都重置为0,然后再返回一个NGX_BUSY,然后nginx就会打印一条no live upstreams ,最后又回到原始状态,接着进行转发了。
这就解释了no live upstreams之后还能正常访问。
重新看配置文件,如果其中一台有一次失败,nginx就会认为它已经死掉,然后就会把以后的流量全都打到另一台上面,当另外一台也有一次失败的时候,就认为两个都死掉了,然后quick recovery,然后打印一条日志。
这样推算的话会带来另一个问题:如果几台同时认定一台后端已经死掉的时候,会造成流量的不均衡。
然后看了一下zabbix,验证了猜想:
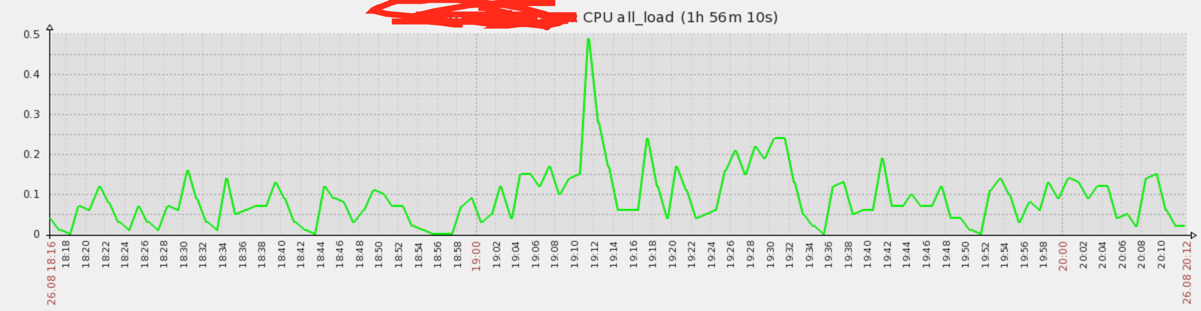
高峰就是出现bug的时候。
解决方法其实很简单:加机器,但是为了一个这样回调的不重要的业务加机器好像不太划算,所以只是找到了问题的原因,之后看能不能通过代码层的优化解决一下这个问题。