PHP8JIT是什么
2020-07-16
在谈JIT之前我们先回到比较根本的一个问题。
怎么优化 PHP 性能
- 方案1,迁移到性能更好的语言上,如Go、Java、C++。
- 方案2,通过 RPC 将功能分离出来用其它语言实现,让 PHP 做更少的事情。
- 方案3,写 PHP 扩展,在性能瓶颈地方换 C/C++。
- 方案4,优化 PHP语言本身的性能。
方案1
方案1的问题在于成本问题,如果代码库已经很大的话,迁移是个非常耗费成本的工作,团队将不但放弃多年的经验积累,而且整个团队成员重新学习也是个成本很高的事情。而且PHP语言的数据结构和内置函数,可以几乎直接地描述和处理实际业务,PHP是计算机与现实业务的最直接胶合剂。这也是我一直喜欢PHP的原因。
方案2
方案2是最保险的方案,我们现在也是这样做的,把一些计算比较多的放在Java执行,通过RPC调用。但是PHP本身的机制以及我们实际业务的场景带来的最大问题是IO场景非常多,而PHP本身也没有多线程和异步IO的机制,所以我们现在是依赖RPC提供的并行和异步处理,但这样也不是最优的方案,还是需要等待一定的时长,而这个等待目前来看又是必须的,所以也就是JIT在实际项目中的效果不会特别明显的原因。
方案3
方案3看起来美好,实际执行起来却很难,一般来说性能瓶颈并不会很显著,大多是不断累加的结果,加上 PHP 扩展开发成本高,这种方案一般只用在公共且变化不大的基础库上,所以这种方案解决不了多少问题。
方案4
所以我们只能想方案4,也就是优化PHP的性能了。
更快的 PHP
同样,PHP的性能优化也有很方案:
- 方案1,PHP语言层面的优化。
- 方案2,优化 PHP 的官方实现(也就是 Zend以及JIT)。
- 方案3,将 PHP 编译成其它语言的 bytecode(字节码),借助其它语言的虚拟机(如 JVM)来运行。
- 方案4,将 PHP 转成 C/C++,然后编译成本地代码。
- 方案5,开发更快的 PHP 虚拟机。
方案1
PHP 语言层面的优化是最简单可行的,比如xhprof,也是我们之前包括现在一直在做的事情。但这个也只能优化一部分,并不能很好的解决我们的问题。
方案2
涉及我们的主题,放在后面说。
方案3
开发一个高性能的虚拟机不是件简单的事情,JVM 花了十多年才达到现在的性能,那是否能直接利用这些高性能的虚拟机来优化 PHP 的性能呢?这就是方案3的思路。
虽然看起来很美好,但实际上VM 总是为某个语言优化的,和器官移植一样,其它语言在上面实现会遇到很多瓶颈,比如动态的方法调用,所以这个方案很多大佬都实现并测试过,没有什么好结果。
方案4
它正是 HPHPc(HHVM 的前身)的做法,原理是将 PHP 代码转成 C++,然后编译为本地文件,可以认为是一种 AOT(ahead of time)的方式。
以下是实现的一个截图,可以通过它来大概了解:
[image:211020D8-932A-46B4-B2FF-C5B3A692DE4C-4107-000084AA49C945D3/hiphop-vm.png]
这种做法的最大优点是实现简单(相对于一个 VM 来说),而且能做很多编译优化(因为是离线的,慢点也没事),比如上面的例子就将-1优化掉了,但它很难支持 PHP 中的很多动态的方法,如 eval()、create_function(),因为这就得再内嵌一个 interpreter,成本不小,所以 HPHPc 干脆就直接不支持这些语法。
但由于他对于开发者并不友善,而且Facebook庞大的程序库使得开发者在进行程序更动时,必须等待数个小时的编译,所以HipHop在2013年被官方弃用 。
方案5
实现 PHP 语言不仅仅只是实现一个虚拟机那么简单,PHP 语言本身还包括了各种扩展,这些扩展和语言是一体的,Zend 不辞辛劳地实现了各种你可能会用到的功能。如果分析过 PHP 的代码,就会发现它的 C 代码除去空行注释后居然还有80+万行,而你猜其中 Zend 引擎部分有多少?只有不到10万行。
对于开发者来说这不是什么坏事(这也是我写PHP非常舒服的原因,大佬们已经做了很多事情,而且我还不用引入那么多其他库),但对于引擎实现者来说就很悲剧了,我们可以拿 Java 来进行对比,写个 Java 的虚拟机只需实现字节码解释及一些基础的 JNI 调用,Java 绝大部分内置库都是用 Java 实现的,所以如果不考虑性能优化,单从工作量看,实现 PHP 虚拟机比 JVM 要难得多(个人观点,Java大佬们不要喷我)。
接下来是 Interpreter 的实现,在解析完 PHP 后会生成 HHVM 自己设计的一种 Bytecode,存储在 ~/.hhvm.hhbc(SQLite 文件) 中以便重用,在执行 Bytecode 时和 Zend 类似,也是将不同的字节码放到不同的函数中去实现。
正是因为有了 Interpreter,HHVM 在对于 PHP 语法的支持上比 HPHPc 有明显改进,理论上做到完全兼容官方 PHP,但仅这么做在性能并不会比 Zend 好多少,由于无法确定变量类型,所以需要加上类似上面的条件判断语句,但这样的代码不利于现代 CPU 的执行优化。
对于这样的问题,就得靠 JIT 来优化了。
HHVM实现 JIT 及优化
那么究竟什么是 JIT?如何实现一个 JIT?
在动态语言中基本上都会有个 eval 方法,可以传给它一段字符串来执行,JIT 做的就是类似的事情,只不过它要拼接不是字符串,而是不同平台下的机器码,然后进行执行,但如何用 C 来实现呢?比如下面这段代码:
我们要实现
long add4(long num) {
return num + 4;
}
转化为JIT就是:
unsigned char code[] = {
0x48, 0x89, 0xf8, // mov %rdi, %rax
0x48, 0x83, 0xc0, 0x04, // add $4, %rax
0xc3 // ret
};
memcpy(m, code, sizeof(code));
然而手工编写机器码很容易出错,所以最好的有一个辅助的库,比如的 Mozilla 的 Nanojit 以及 LuaJIT 的 DynASM (PHP8中的JIT就使用了这个库,我后面会单独讲它),但 HHVM 并没有使用这些,而是自己实现了一个只支持 x64 的,通过 mprotect 的方式来让代码可执行(在Linux中,mprotect()函数可以用来修改一段指定内存区域的保护属性)。
但为什么 JIT 代码会更快?你可以想想其实用 C++ 编写的代码最终编译出来也是机器码,如果只是将同样的代码手动转成了机器码,那和 GCC 生成出来的有什么区别呢?在 JIT 中更重要的优化是根据类型来生成特定的指令,从而大幅减少指令数和条件判断。
HHVM 首先通过 interpeter 来执行,那它会在时候使用 JIT 呢?常见的 JIT 触发条件有 2 种:
- trace:记录循环执行次数,如果超过一定数量就对这段代码进行 JIT。
- method:记录函数执行次数,如果超过一定数量就对整个函数进行 JIT,甚至直接 inline。
(这两种方法在PHP8JIT中都实现了)
JIT 的关键是猜测类型,因此某个变量的类型要是老变就很难优化,于是 HHVM 的工程师开始考虑在 PHP 语法上做手脚,加上类型的支持,推出了一个新语言 - Hack
<?hh
class Point2 {
public float $x, $y;
function __construct(float $x, float $y) {
$this->x = $x;
$this->y = $y;
}
}
注意到float了吗?有了静态类型可以让 HHVM 更好地优化性能,但这也意味着和 PHP 语法不兼容,只能使用 HHVM。
插一个八卦,这里也就是为什么鸟哥说PHP面临分裂的风险。
方案2
重新来说方案2。
Zend 的执行过程可以分为两部分:
- 将 PHP 编译为 opcode
- 执行 opcode
所以优化 Zend 可以从这两方面来考虑。
PHP底层数据结构,函数,内存的优化已经完成了,也就是PHP7,比如减少程序运作时搬动的内存位数,PHP7 中储存变量的数据架构 zval 从 24 位 缩减至 16 位、Hashtable 从 72 位减少至 56 位。除了从减少内存的使用着手外,还使用了CPU 的 Cache line 的运作原理,了解程序代码如何与 CPU 互动、编译程序如何在新 CPU 架构下编译程序代码等细节。
优化 opcode 是一种常见的做法,可以避免重复解析 PHP,而且还能做一些静态的编译优化,比如 Zend Optimizer Plus ,也就是现在的Opcache,将预编译后的PHP文件存储在共享内存中以供以后的使用,避免从磁盘读取文件在进行解释的重复过程,减少时间和内存的消耗。
但由于 PHP 语言的动态性,这种优化方法是有局限性的。另一种考虑是优化 opcode 架构本身,如基于寄存器的方式,但这种做法修改起来工作量太大,性能提升也不会特别明显,所以投入产出比不高。
另一个方法是优化 opcode 的执行,首先简单提一下 Zend 是如何执行的,Zend 的 interpreter(也叫解释器)在读到 opcode 后,会根据不同的 opcode 调用不同函数(其实有些是 switch,不过为了描述方便我简化了),然后在这个函数中执行各种语言相关的操作(感兴趣的话可看看《深入理解 PHP 内核》这本书),所以 Zend 中并没有什么复杂封装和间接调用,作为一个解释器来说已经做得很好了。
想要提升 Zend 的执行性能,就需要对程序的底层执行有所解,比如函数调用其实是有开销的,所以能通过 Inline threading 优化掉,它的原理就像 C 语言中的 inline 关键字那样,但它是在运行时将相关的函数展开,然后依次执行(只是打个比方,实际实现不太一样),同时还避免了 CPU 流水线预测失败导致的浪费。
现在PHP8增加了JIT,在Opcache上的基础上进行的优化。
好了,下面开始我们的正题。
PHP8 JIT
性能测评
这个是纯CPU的测试,效果比较明显,php web项目现在IO的瓶颈更大,所以实际项目效果不会这么好,具体可以等stable版本出来后再实际测试。
PHP JIT流程
先看看鸟哥公众号上的一张图:
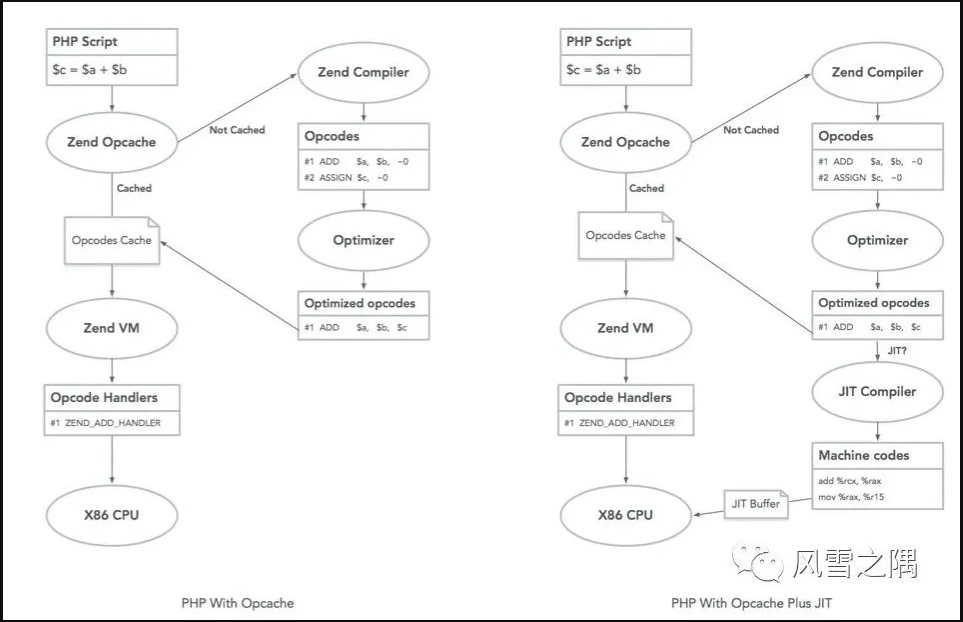
他这个图实际上画错了,图上画的有了Opcache之后就不JIT了,实际上是会的。
后来鸟哥在blog上把图更新了,是这样:
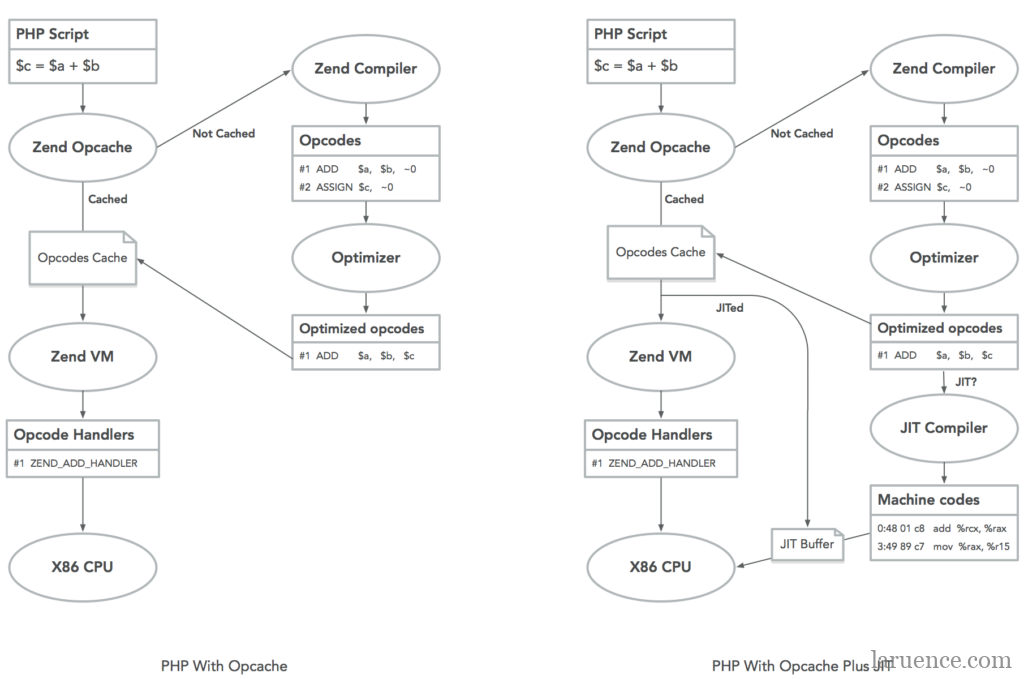
下面这个图也是对的:
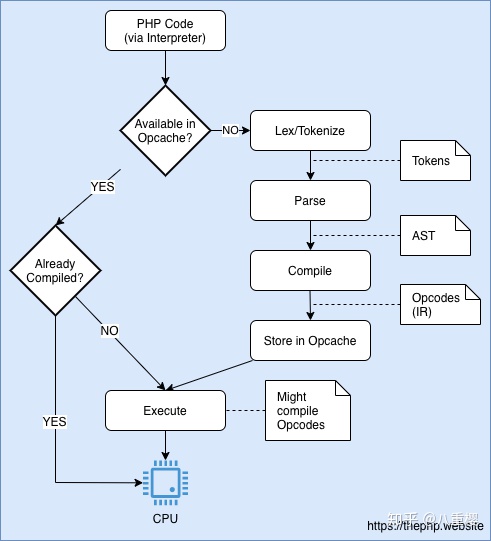
JIT实际上是对Opcache的优化,原本需要Zend VM作为中间层解释opcode,现在可以直接用JIT作为机器指令执行。所以中间少了一层执行过程,性能得到了提高。
一个JIT和一个调用printf的程序没有本质的区别,只是JIT产生的是机器代码,而不是像Hello, World!这样的消息。
PHP 的 JIT 使用了名为DynASM (Dynamic Assembler) 的库,该库将一种特定格式的一组 CPU 指令映射为许多不同 CPU 类型的汇编代码。因此,编译器只需要使用 DynASM 就可以将 opcodes 转换为特定结构体的机器码。
这里有一个问题:
如果预加载能够在执行之前将 PHP 代码解析为 Opcodes,并且 DynASM 可以将 Opcodes 编译为机器码 (Just In Time 编译) ,为什么我们不立即使用运行前编译 (Ahead of Time 编译) 立即编译 PHP 呢?
答案是PHP 是弱类型语言,这意味着在 Zend VM 尝试执行某个操作码之前, PHP 通常不知道变量的类型。
JIT编译
先看一下php 8 JIT的dasc文件。
php-src/zend_jit_x86.dasc at jit-dynasm · zendtech/php-src · GitHub
然后源码查看了下JIT是如何实现的,包括以下两个部分:
- JIT编译机制
- Opcache在opcode handler的替换。
- 检查每个功能执行的JIT启动条件。
- JIT编译处理内容
- 使用DynASM生成data flow graph, call graph, SSA代码。
- 运行Opcache handler替换后生成的代码。
JIT编译机制
php代码执行流程
当我运行以下命令时会发生什么?
php foo.php
- sapi/cli/php_cli.c 执行main函数
- Zend/zend.c 调用zend_execute_scripts 函数
- 用zend_compile_file函数编译
op_array = zend_compile_file(file_handle, type);
上述代码将文件编译为一系列字节码。
- 执行zend_execute函数
zend_execute(op_array, retval);
这个命令用来执行字节码。
op_array
在 Zend/zend_compile.h
_zend_op_array结构体:
struct _zend_op_array {
/* Common elements */
zend_uchar type;
zend_uchar arg_flags[3]; /* bitset of arg_info.pass_by_reference */
...
uint32_t last; /* number of opcodes */
zend_op *opcodes;
...
};
其中的zend_op *opcodes;如下:
struct _zend_op {
const void *handler;
znode_op op1;
znode_op op2;
znode_op result;
uint32_t extended_value;
uint32_t lineno;
zend_uchar opcode;
zend_uchar op1_type;
zend_uchar op2_type;
zend_uchar result_type;
};
_zend_op_array 和 _zend_op是一对多的关系。
execute_ex函数
in Zend/zend_vm_execute.h
每个zend_op的handler的执行
while (1) { ...
if (UNEXPECTED((ret = ((opcode_handler_t)OPLINE->handler)()) != 0)){
...
return;
}
...
} ...
使用JIT编译执行
没有JIT的话对每个op_array执行以下操作:
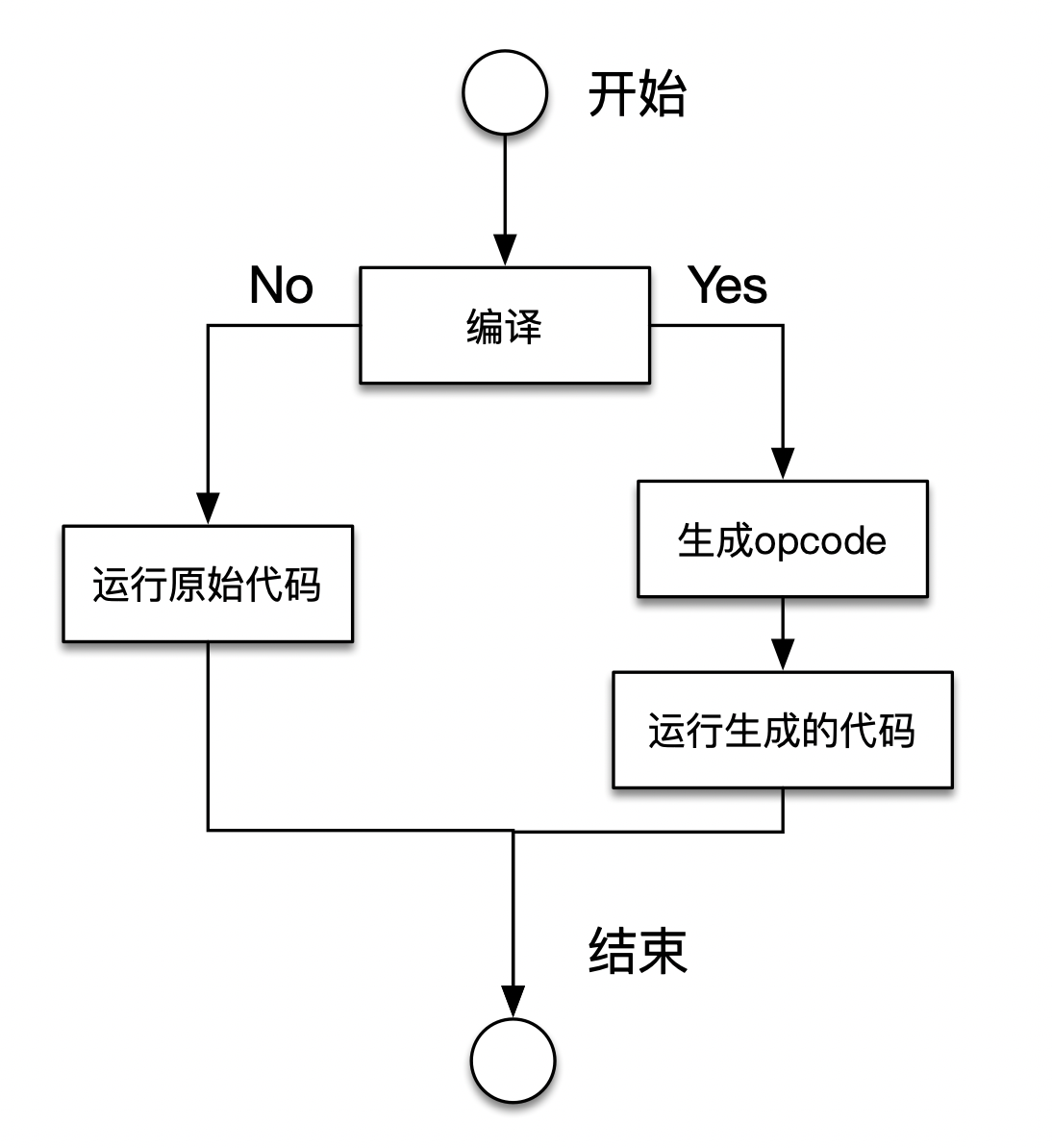
JIT在编译时替换handler:
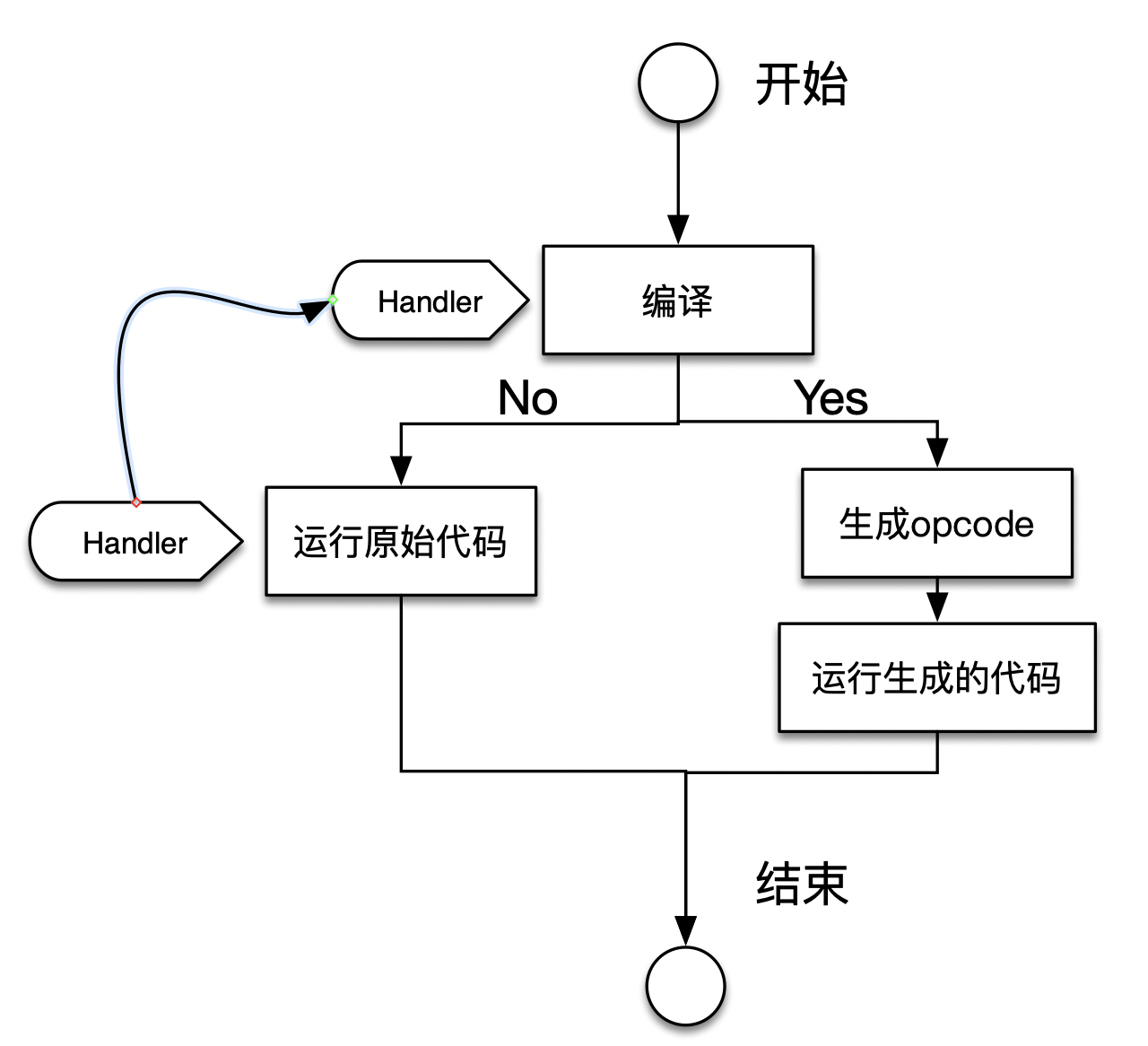
Opcache的处理
在启动时替换zend_compile_file函数
in ext/opcache/ZendAccelerator.c
static int accel_startup(zend_extension *extension) {
...
/* Override compiler */
accelerator_orig_compile_file = zend_compile_file;
zend_compile_file = persistent_compile_file;
...
}
persistent_compile_file有什么用?
- 缓存编译的数据结构
- Opcache独特的优化
新增:替换用于JIT编译的handler(仅在启用JIT时)。
注意了,JIT在这里开始!
persistent_compile_file
/* zend_compile() replacement */
zend_op_array *persistent_compile_file(zend_file_handle *file_handle, int type) {
...
// 如果尚未缓存
if (!persistent_script) {
// 编译
persistent_script = opcache_compile_file(...);
// 编译成功的话进行下一步
if (persistent_script) {
persistent_script = cache_script_in_shared_memory(...);
}
}
} ...
通往JIT之路
从ext/opcache/ZendAccelerator.c 的
static zend_persistent_script *cache_script_in_shared_memory( … )
到 ext/opcache/zend_persist.c 的
zend_persistent_script *zend_accel_script_persist( ... )
到 ext/opcache/zend_persist.c
static void zend_persist_op_array_ex( ... )
到ext/opcache/jit/zend_jit.c 的
ZEND_API int zend_jit_op_array(
zend_op_array *op_array, zend_script *script)
在这个函数中进行handler的替换。
JIT编译的触发
in ext/opcache/jit/zend_jit.h
这个也就是鸟哥公众号里说的JIT触发策略
有以下几种选择
0 ZEND_JIT_ON_SCRIPT_LOAD PHP脚本载入的时候就JIT。
1 ZEND_JIT_ON_FIRST_EXEC 当函数第一次被执行时JIT。
2 ZEND_JIT_ON_PROF_REQUEST 在一次运行后,JIT调用次数最多的百分之(opcache.prof_threshold * 100)的函数。
3 ZEND_JIT_ON_HOT_COUNTERS 当函数/方法执行超过N(N和opcache.jit_hot_func相关)次以后JIT。
4 ZEND_JIT_ON_DOC_COMMENT 当函数方法的注释中含有@jit的时候对它进行JIT。
5 ZEND_JIT_ON_HOT_TRACE 当一个Trace执行超过N次(和opcache.jit_hot_loop, jit_hot_return等有关)以后JIT。
ZEND_JIT_ON_SCRIPT_LOAD
in ext/opcache/jit/zend_jit.c
return zend_real_jit_func(op_array, script, NULL);
Opcache处理op_array时进行编译,从这个意义上讲,这不是 Just In Time。
ZEND_JIT_ON_FIRST_EXEC
in ext/opcache/jit/zend_jit.c
opline->handler = (const void*)zend_runtime_jit;
首次执行zend_runtime_jit函数无条件启动JIT编译:
static void ZEND_FASTCALL zend_runtime_jit(void) {
...
/* perform real JIT for this function */
// 执行JIT编译
zend_real_jit_func(op_array, NULL, NULL);
...
}
ZEND_JIT_ON_PROF_REQUEST
opline->handler = zend_jit_profile_helper;
zend_jit_profile_helper计算每个op_array的执行次数。
in ext/opcache/jit/zend_jit_vm_helpers.c
ZEND_OPCODE_HANDLER_RET ZEND_FASTCALL zend_jit_profile_helper(ZEND_OPCODE_HANDLER_ARGS)
{
zend_op_array *op_array = (zend_op_array*)EX(func);
zend_jit_op_array_extension *jit_extension = (zend_jit_op_array_extension*)ZEND_FUNC_INFO(op_array);
// 获取原本的handler
zend_vm_opcode_handler_t handler = (zend_vm_opcode_handler_t) jit_extension->orig_handler;
// 这个op_array的执行次数
++*(uintptr_t*)(EX(run_time_cache) + zend_jit_profile_counter_rid);
// 所有的op_array的执行次数总和
++zend_jit_profile_counter;
// 执行本来的处理
ZEND_OPCODE_TAIL_CALL(handler);
}
Opcache资源释放时进行JIT编译。
in ext/opcache/jit/zend_jit.c
void zend_jit_check_funcs(HashTable *function_table, zend_bool is_method) {
...
zend_ulong counter = (zend_ulong)ZEND_COUNTER_INFO(op_array);
if (((double)counter / (double)zend_jit_profile_counter) > ZEND_JIT_PROF_THRESHOLD) {
zend_real_jit_func(op_array, NULL, NULL);
}
...
}
对执行时间占比超过阈值的op_array使用JIT,而是由最初的请求决定。
ZEND_JIT_ON_HOT_COUNTERS
in ext/opcache/jit/zend_jit.c
return zend_jit_setup_hot_counters(op_array);
以基本块为单位测量执行次数
static int zend_jit_setup_hot_counters(zend_op_array *op_array) {
...
opline->handler = (const void*)zend_jit_func_counter_helper;
// Control Flow Graph
for (i = 0; i < cfg.blocks_count; i++) {
...
op_array->opcodes[cfg.blocks[i].start].handler = (const void*)zend_jit_loop_counter_helper;
}
...
}
in ext/opcache/jit/zend_jit_vm_helpers.c
每次执行时,都会去减hot counter,如果小于等于0,则进行编译。
void ZEND_FASTCALL zend_jit_func_counter_helper(void) {
...
*(jit_extension->counter) -= ((ZEND_JIT_COUNTER_INIT + JIT_G(hot_func) - 1) / JIT_G(hot_func));
if (UNEXPECTED(*(jit_extension->counter) <= 0)) {
*(jit_extension->counter) = ZEND_JIT_COUNTER_INIT;
// 恢复处理程序并执行JIT
zend_jit_hot_func(execute_data, opline);
ZEND_OPCODE_RETURN();
} else {
zend_vm_opcode_handler_t handler = (zend_vm_opcode_handler_t)jit_extension->orig_handlers[opline - EX(func)->op_array.opcodes];
ZEND_OPCODE_TAIL_CALL(handler);
}
}
zend_jit_loop_counter_helper 也是同样的执行逻辑。
ZEND_JIT_ON_DOC_COMMENT
if (zend_needs_manual_jit(op_array)) {
return zend_real_jit_func(op_array, script, NULL);
} else {
return SUCCESS;
}
仅适用于在DocComment中指定@jit的函数,Opcache处理op_array时进行编译,当然这也不是“Just In Time”。
JIT编译处理内容
zend_real_jit_func
in ext/opcache/jit/zend_jit.c
static int zend_real_jit_func(zend_op_array *op_array, zend_script *script, const zend_op *rt_opline) {
解析JIT编译(使用Opcache)
- 控制流程图(Control Flow Graph,CFG)的构建
- 数据流(data flow)分析(ZEND_JIT_LEVEL_OPT_FUNC)
- 调用图(call graph)构造(ZEND_JIT_LEVEL_OPT_FUNCS)
代码的生成
- 根据opcode生成机器码
- 使用DynASM作为代码生成机制
代码生成
in ext/opcache/jit/zend_jit.c
JIT编译的主体
static int zend_jit(zend_op_array *op_array, zend_ssa *ssa, const zend_op *rt_opline) {
...
// 编译op_array中包含的每个opcode
switch (opline->opcode) {
...
case ZEND_PRE_INC:
case ZEND_PRE_DEC:
case ZEND_POST_INC:
case ZEND_POST_DEC:
if (!zend_jit_inc_dec(&dasm_state, opline, op_array, ssa)) {
goto jit_failure;
}
goto done;
}
}
代码生成的实现
以DynASM格式(.dasc)描述
in ext/opcache/jit/zend_jit_x86.dasc
static int zend_jit_inc_dec(dasm_State **Dst, const zend_op *opline, const zend_op_array *op_array, uint32_t op1_info, zend_jit_addr op1_addr, uint32_t op1_def_info, zend_jit_addr op1_def_addr, uint32_t res_use_info, uint32_t res_info, zend_jit_addr res_addr, int may_overflow, int may_throw)
{
if (op1_info & ((MAY_BE_UNDEF|MAY_BE_ANY)-MAY_BE_LONG)) {
| IF_NOT_ZVAL_TYPE op1_addr, IS_LONG, >2
}
if (opline->opcode == ZEND_POST_INC || opline->opcode == ZEND_POST_DEC) {
| ZVAL_COPY_VALUE res_addr, res_use_info, op1_addr, MAY_BE_LONG, ZREG_R0, ZREG_R1
}
if (!zend_jit_update_regs(Dst, op1_addr, op1_def_addr, MAY_BE_LONG)) {
return 0;
}
if (opline->opcode == ZEND_PRE_INC || opline->opcode == ZEND_POST_INC) {
| LONG_OP_WITH_CONST add, op1_def_addr, Z_L(1)
} else {
| LONG_OP_WITH_CONST sub, op1_def_addr, Z_L(1)
}
...
}
根据dynasm.lua转换为zend_jit_x86.c
DynASM
之后单独讲这个,简单来说DynASM就是一个方便写汇编的框架。
in ext/opcache/jit/zend_jit_x86.dasc
if (opline->opcode == ZEND_PRE_INC || opline->opcode == ZEND_POST_INC) {
| inc aword [FP + opline->op1.var]
} else {
| dec aword [FP + opline->op1.var]
}
生成以下C代码
in ext/opcache/jit/zend_jit_x86.c
if (opline->opcode == ZEND_PRE_INC || opline->opcode == ZEND_POST_INC) {
//| inc aword [FP + opline->op1.var]
dasm_put(Dst, 749, opline->op1.var);
} else {
//| dec aword [FP + opline->op1.var] dasm_put(Dst, 755, opline->op1.var);
}
简单描述一下就是

// 处理所有操作码后之后,将生成的机器语言作为处理程序执行
handler = dasm_link_and_encode(&dasm_state, op_array, &ssa->cfg, rt_opline, NULL);
DynASM
最后说一下为什么要用DynASM?
一个简单的JIT最困难的部分是编写目标CPU可以理解的指令。例如在x86-64平台,push rbp这个指令被编码成0x55。这样的编码人几乎看不懂。DynASM采用了一个新颖的方式, 可以在JIT中混合使用汇编代码和C代码,从而可以用一个非常自然和可读的方式实现JIT。它支持很多CPU架构,所以不会因为它对硬件的支持而受到限制。DynASM也格外小巧, 其整个运行时库都包含在500行的头文件中。
所以简单来说DynASM就是一个方便写汇编的框架。
DynASM 是为 luajit 编写的 JIT 汇编预处理器和微型运行时库 (简单来讲, DynASM完成两个工作, 一个是预处理, 把你写的汇编指令 (对, 没有Elixir, DynASM并不能直接把逻辑变成汇编, 需要你手动把你的逻辑用汇编语言重写一遍, 因此性能也取决于你的汇编代码写的好坏) 变成真正的二进制机器码, 另一个是提供一个微型运行时, 来处理那些必须推迟到运行时才能执行的代码).
一个JIT的例子
brainfuck
++++++++++[>+++++++>++++++++++>+++>+<<<<-]
>++.>+.+++++++..+++.>++.<<+++++++++++++++.
>.+++.------.--------.>+.>.
这个编译完是输出
Hello World!
#include <stdio.h>
#include <stdlib.h>
#define TAPE_SIZE 30000
#define MAX_NESTING 100
typedef struct bf_state
{
unsigned char* tape;
unsigned char (*get_ch)(struct bf_state*);
void (*put_ch)(struct bf_state*, unsigned char);
} bf_state_t;
#define bad_program(s) exit(fprintf(stderr, "bad program near %.16s: %s\n", program, s))
static void bf_interpret(const char* program, bf_state_t* state)
{
const char* loops[MAX_NESTING];
int nloops = 0;
int n;
int nskip = 0;
unsigned char* tape_begin = state->tape - 1;
unsigned char* ptr = state->tape;
unsigned char* tape_end = state->tape + TAPE_SIZE - 1;
for(;;) {
switch(*program++) {
case '<':
for(n = 1; *program == '<'; ++n, ++program);
if(!nskip) {
ptr -= n;
while(ptr <= tape_begin)
ptr += TAPE_SIZE;
}
break;
case '>':
for(n = 1; *program == '>'; ++n, ++program);
if(!nskip) {
ptr += n;
while(ptr > tape_end)
ptr -= TAPE_SIZE;
}
break;
case '+':
for(n = 1; *program == '+'; ++n, ++program);
if(!nskip)
*ptr += n;
break;
case '-':
for(n = 1; *program == '-'; ++n, ++program);
if(!nskip)
*ptr -= n;
break;
case ',':
if(!nskip)
*ptr = state->get_ch(state);
break;
case '.':
if(!nskip)
state->put_ch(state, *ptr);
break;
case '[':
if(nloops == MAX_NESTING)
bad_program("Nesting too deep");
loops[nloops++] = program;
if(!*ptr)
++nskip;
break;
case ']':
if(nloops == 0)
bad_program("] without matching [");
if(*ptr)
program = loops[nloops-1];
else
--nloops;
if(nskip)
--nskip;
break;
case 0:
if(nloops != 0)
program = "<EOF>", bad_program("[ without matching ]");
return;
}
}
}
static void bf_putchar(bf_state_t* s, unsigned char c)
{
putchar((int)c);
}
static unsigned char bf_getchar(bf_state_t* s)
{
return (unsigned char)getchar();
}
static void bf_run(const char* program)
{
bf_state_t state;
unsigned char tape[TAPE_SIZE] = {0};
state.tape = tape;
state.get_ch = bf_getchar;
state.put_ch = bf_putchar;
bf_interpret(program, &state);
}
int main(int argc, char** argv)
{
if(argc == 2) {
long sz;
char* program;
FILE* f = fopen(argv[1], "r");
if(!f) {
fprintf(stderr, "Cannot open %s\n", argv[1]);
return 1;
}
fseek(f, 0, SEEK_END);
sz = ftell(f);
program = (char*)malloc(sz + 1);
fseek(f, 0, SEEK_SET);
program[fread(program, 1, sz, f)] = 0;
fclose(f);
bf_run(program);
return 0;
} else {
fprintf(stderr, "Usage: %s INFILE.bf\n", argv[0]);
return 1;
}
}
这个程序用来渲染曼德博集合(Mandelbrot set):
gcc -o tutorial tutorial.c
./tutorial mandelbrot.bf

./tutorial mandelbrot.bf 67.48s user 0.59s system 44% cpu 2:33.30 total
花了67.48s
然后用dynasm重新写一下
||#if ((defined(_M_X64) || defined(__amd64__)) != X64) || (defined(_WIN32) != WIN)
#error "Wrong DynASM flags used: pass `-D X64` and/or `-D WIN` to dynasm.lua as appropriate"
#endif
#include <stdio.h>
#include <stdlib.h>
#include "luajit-2.0/dynasm/dasm_proto.h"
#include "luajit-2.0/dynasm/dasm_x86.h"
#if _WIN32
#include <Windows.h>
#else
#include <sys/mman.h>
#if !defined(MAP_ANONYMOUS) && defined(MAP_ANON)
#define MAP_ANONYMOUS MAP_ANON
#endif
#endif
static void* link_and_encode(dasm_State** d)
{
size_t sz;
void* buf;
dasm_link(d, &sz);
#ifdef _WIN32
buf = VirtualAlloc(0, sz, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
#else
buf = mmap(0, sz, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
#endif
dasm_encode(d, buf);
#ifdef _WIN32
{DWORD dwOld; VirtualProtect(buf, sz, PAGE_EXECUTE_READ, &dwOld); }
#else
mprotect(buf, sz, PROT_READ | PROT_EXEC);
#endif
return buf;
}
#define TAPE_SIZE 30000
#define MAX_NESTING 100
typedef struct bf_state
{
unsigned char* tape;
unsigned char (*get_ch)(struct bf_state*);
void (*put_ch)(struct bf_state*, unsigned char);
} bf_state_t;
#define bad_program(s) exit(fprintf(stderr, "bad program near %.16s: %s\n", program, s))
static void(* bf_compile(const char* program) )(bf_state_t*)
{
unsigned loops[MAX_NESTING];
int nloops = 0;
int n;
dasm_State* d;
unsigned npc = 8;
unsigned nextpc = 0;
|.if X64
|.arch x64
|.else
|.arch x86
|.endif
|.section code
dasm_init(&d, DASM_MAXSECTION);
|.globals lbl_
void* labels[lbl__MAX];
dasm_setupglobal(&d, labels, lbl__MAX);
|.actionlist bf_actions
dasm_setup(&d, bf_actions);
dasm_growpc(&d, npc);
|.if X64
|.define aPtr, rbx
|.define aState, r12
|.if WIN
|.define aTapeBegin, rsi
|.define aTapeEnd, rdi
|.define rArg1, rcx
|.define rArg2, rdx
|.else
|.define aTapeBegin, r13
|.define aTapeEnd, r14
|.define rArg1, rdi
|.define rArg2, rsi
|.endif
|.macro prepcall1, arg1
| mov rArg1, arg1
|.endmacro
|.macro prepcall2, arg1, arg2
| mov rArg1, arg1
| mov rArg2, arg2
|.endmacro
|.define postcall, .nop
|.macro prologue
| push aPtr
| push aState
| push aTapeBegin
| push aTapeEnd
| push rax
| mov aState, rArg1
|.endmacro
|.macro epilogue
| pop rax
| pop aTapeEnd
| pop aTapeBegin
| pop aState
| pop aPtr
| ret
|.endmacro
|.else
|.define aPtr, ebx
|.define aState, ebp
|.define aTapeBegin, esi
|.define aTapeEnd, edi
|.macro prepcall1, arg1
| push arg1
|.endmacro
|.macro prepcall2, arg1, arg2
| push arg2
| push arg1
|.endmacro
|.macro postcall, n
| add esp, 4*n
|.endmacro
|.macro prologue
| push aPtr
| push aState
| push aTapeBegin
| push aTapeEnd
| mov aState, [esp+20]
|.endmacro
|.macro epilogue
| pop aTapeEnd
| pop aTapeBegin
| pop aState
| pop aPtr
| ret 4
|.endmacro
|.endif
|.type state, bf_state_t, aState
dasm_State** Dst = &d;
|.code
|->bf_main:
| prologue
| mov aPtr, state->tape
| lea aTapeBegin, [aPtr-1]
| lea aTapeEnd, [aPtr+TAPE_SIZE-1]
for(;;) {
switch(*program++) {
case '<':
for(n = 1; *program == '<'; ++n, ++program);
| sub aPtr, n%TAPE_SIZE
| cmp aPtr, aTapeBegin
| ja >1
| add aPtr, TAPE_SIZE
|1:
break;
case '>':
for(n = 1; *program == '>'; ++n, ++program);
| add aPtr, n%TAPE_SIZE
| cmp aPtr, aTapeEnd
| jbe >1
| sub aPtr, TAPE_SIZE
|1:
break;
case '+':
for(n = 1; *program == '+'; ++n, ++program);
| add byte [aPtr], n
break;
case '-':
for(n = 1; *program == '-'; ++n, ++program);
| sub byte [aPtr], n
break;
case ',':
| prepcall1 aState
| call aword state->get_ch
| postcall 1
| mov byte [aPtr], al
break;
case '.':
| movzx r0, byte [aPtr]
| prepcall2 aState, r0
| call aword state->put_ch
| postcall 2
break;
case '[':
if(nloops == MAX_NESTING)
bad_program("Nesting too deep");
if(program[0] == '-' && program[1] == ']') {
program += 2;
| xor eax, eax
| mov byte [aPtr], al
} else {
if(nextpc == npc) {
npc *= 2;
dasm_growpc(&d, npc);
}
| cmp byte [aPtr], 0
| jz =>nextpc+1
|=>nextpc:
loops[nloops++] = nextpc;
nextpc += 2;
}
break;
case ']':
if(nloops == 0)
bad_program("] without matching [");
--nloops;
| cmp byte [aPtr], 0
| jnz =>loops[nloops]
|=>loops[nloops]+1:
break;
case 0:
if(nloops != 0)
program = "<EOF>", bad_program("[ without matching ]");
| epilogue
link_and_encode(&d);
dasm_free(&d);
return (void(*)(bf_state_t*))labels[lbl_bf_main];
}
}
}
static void bf_putchar(bf_state_t* s, unsigned char c)
{
putchar((int)c);
}
static unsigned char bf_getchar(bf_state_t* s)
{
return (unsigned char)getchar();
}
static void bf_run(const char* program)
{
bf_state_t state;
unsigned char tape[TAPE_SIZE] = {0};
state.tape = tape;
state.get_ch = bf_getchar;
state.put_ch = bf_putchar;
bf_compile(program)(&state);
}
int main(int argc, char** argv)
{
if(argc == 2) {
long sz;
char* program;
FILE* f = fopen(argv[1], "r");
if(!f) {
fprintf(stderr, "Cannot open %s\n", argv[1]);
return 1;
}
fseek(f, 0, SEEK_END);
sz = ftell(f);
program = (char*)malloc(sz + 1);
fseek(f, 0, SEEK_SET);
program[fread(program, 1, sz, f)] = 0;
fclose(f);
bf_run(program);
return 0;
} else {
fprintf(stderr, "Usage: %s INFILE.bf\n", argv[0]);
return 1;
}
}
为了编译, 首先需要通过 DynASM 预处理程序运行它. 预处理器是用 Lua 编写的, 因此首先编译一个 minimal Lua 解释器 (如果有luajit也可以直接用luajit运行dynasm.lua, 就可以省略这一步):
gcc -o minilua luajit-2.0/src/host/minilua.c
然后运行 DynASM 预处理器:
./minilua luajit-2.0/dynasm/dynasm.lua -o tutorial.posix64.c -D X64 tutorial.c
完成预处理后, 调用 C 编译器:
gcc -o tutorial tutorial.posix64.c
然后, 我们可以运行生成的可执行文件, 该可执行文件将很快运行 Mandelbrot set:
./tutorial mandelbrot.bf
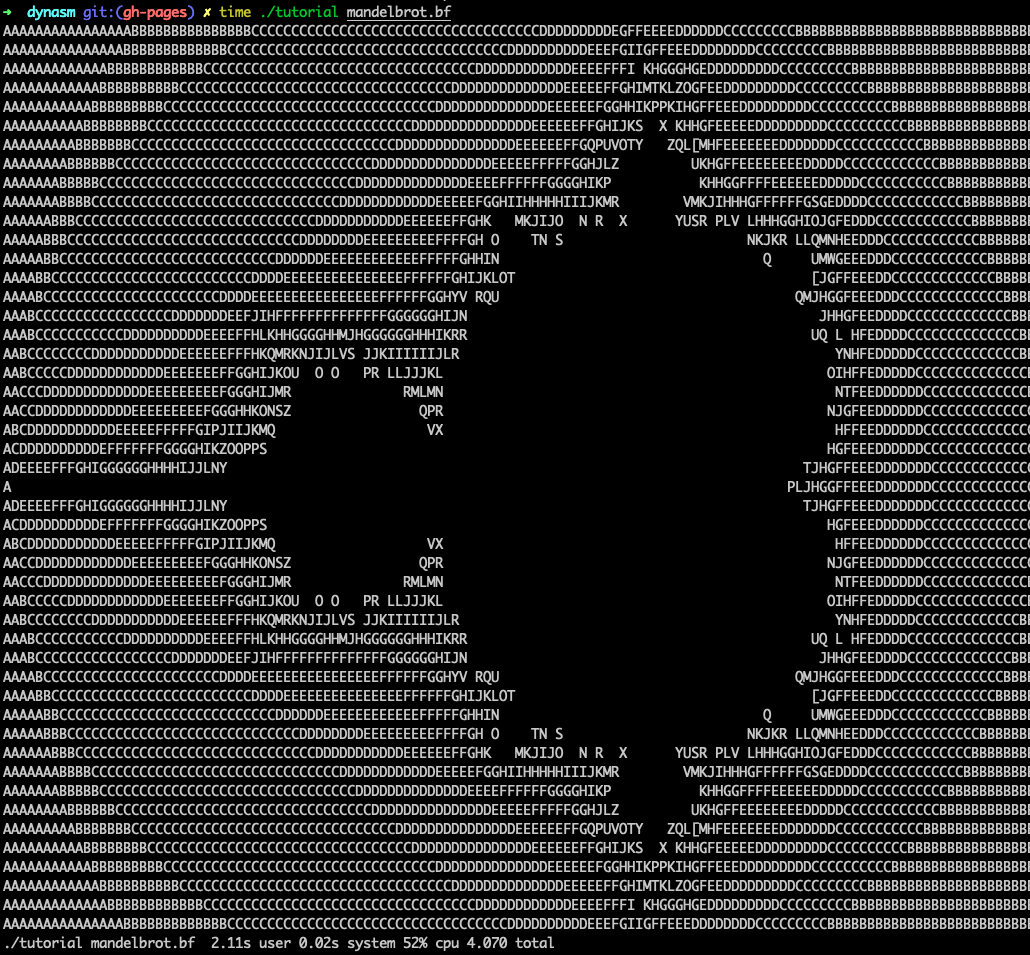
只花了2.11s,jit之前是67.48s,jit后是2.11s,性能提升了接近32倍。
参考的文章,感谢巨人们的肩膀:
PHP8新特性JIT使用简介
The Unofficial DynASM Documentation
HHVM 是如何提升 PHP 性能的? - wuduoyi
https://learnku.com/php/t/44968